Before we talk about how to improve a RAG system, we should first understand what RAG is and why it matters. RAG (Retrieval-Augmented Generation) is a technique often used to improve the output quality of large language models (LLMs).
Think of an LLM as a well-read librarian: it has an impressive collection of books and can answer many questions based on what it has read. But just like a librarian who only knows what's currently on the shelf, LLMs are limited to the data they were trained on.
One of the biggest challenges with LLMs is that they can "hallucinate"—like a librarian making up details from nonexistent books to appear knowledgeable. This happens because the model tries to be helpful but occasionally generates ideas not grounded in reality.
Additionally, LLMs are trained on data up to a certain point and don't know anything about events after their last update. The screenshot below shows such an example: when I asked Deepseek who the current President of the United States was in March 2025, it reminded me that its knowledge cuts off in July 2024 and told me Joe Biden was the president.
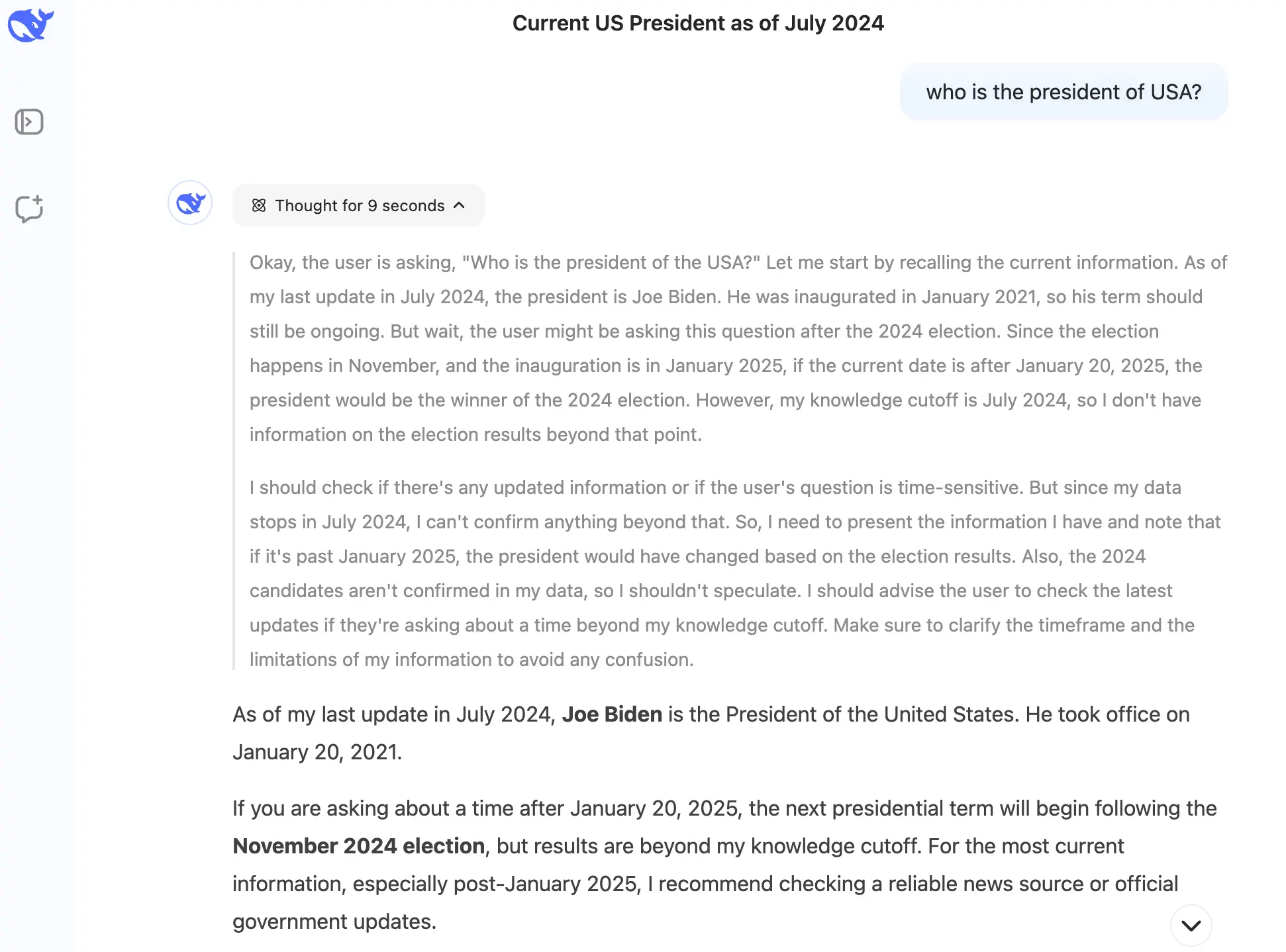
But it's not just outdated information that LLMs struggle with—they also can't access private company data.
This is where RAG comes in. By providing relevant external information to LLMs, RAG helps fill in gaps and ensures that the "librarian" (LLM) can provide more accurate and up-to-date answers.
Key Components of RAG
The following diagram shows what a RAG system looks like. The first step in building a RAG system is indexing your knowledge base, which can include files, websites, emails, and more. Indexing means organizing your data so it can be searched quickly and efficiently—think of it like a book's table of contents, allowing you to jump to the relevant section without flipping through every page.
The diagram below shows an example of vector-based indexing. It starts with data from your knowledge base, where each file is processed and split into chunks. Chunks are smaller pieces of text that are easier to manage. These chunks are then fed into an embedding model, which produces embeddings—numerical vectors that represent the chunk in semantic space. The embeddings capture the semantic meaning of the chunk, not just its literal words.
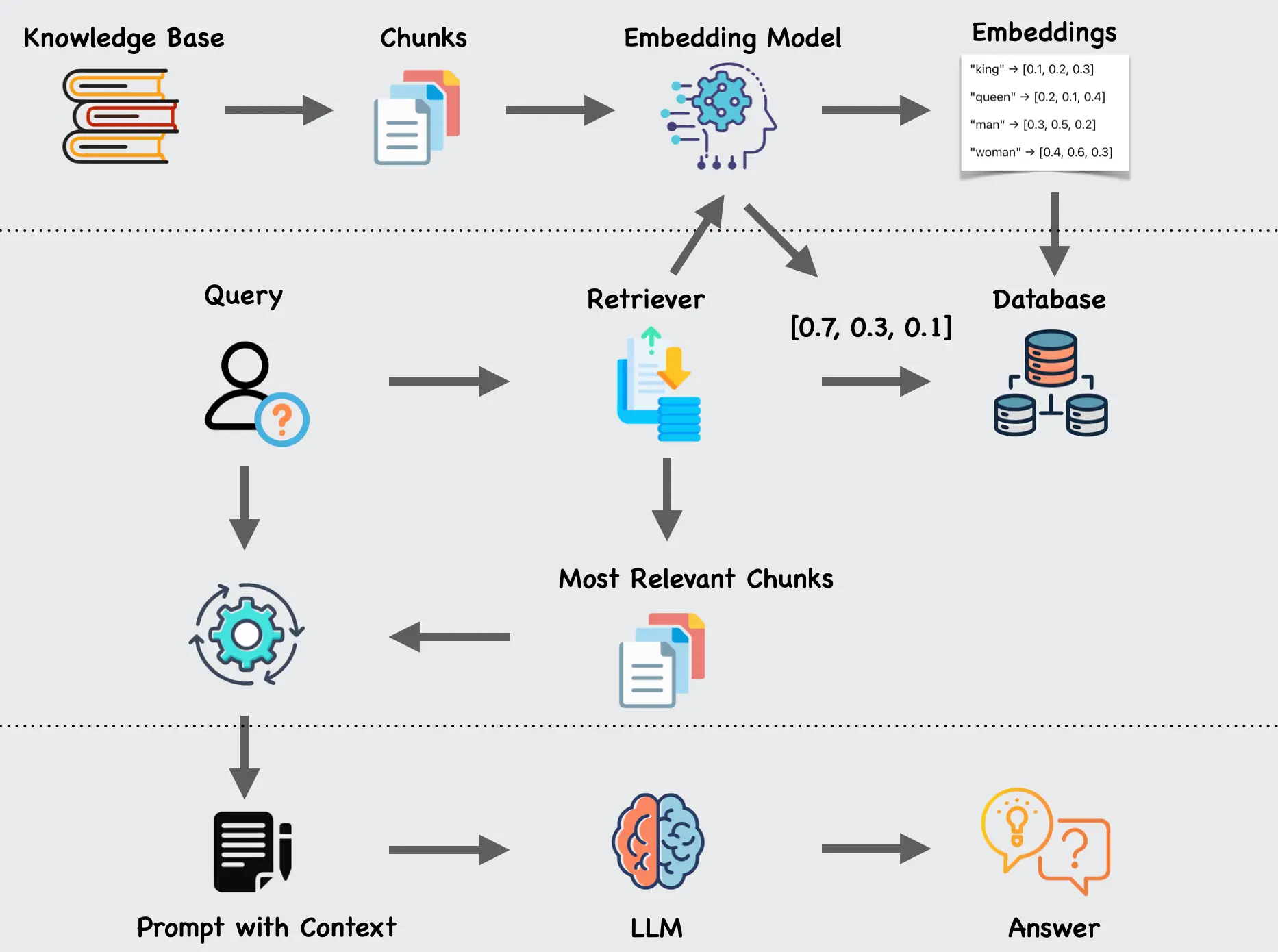
Think of embeddings as points in a coordinate system—the closer they are to each other, the more similar the meanings of the original chunks.
Consider the following chunks and their embeddings:
| Chunk | Embedding |
|---|---|
| I love programming. | [0.1, 0.3, 0.5] |
| I enjoy programming. | [0.2, 0.4, 0.5] |
| Python is great for machine learning. | [0.7, 0.2, 0.1] |
Since the sentences "I love programming" and "I enjoy programming" have similar meanings, their embeddings are also close together. In contrast, "Python is great for machine learning" has a different meaning, leading to a more distant embedding.
Once you have the embeddings, you can store them in a database for later use. Since embeddings are numerical vectors, not plain text, a vector database is typically needed to search through them efficiently. Vector databases are designed to store high-dimensional vectors and perform fast similarity searches.
When a user sends a query to the RAG system, the first step is retrieving relevant chunks that help answer the query. This is handled by a component called the "retriever", which can be divided into two main classes:
-
Sparse Retrievers (keyword-based): These retrieve chunks by matching query keywords with indexed data. An example is BM25, which ranks documents based on keyword frequency and inverse document frequency. A query like "best programming language" retrieves chunks with high-frequency keywords like "best" and "programming language."
-
Dense Retrievers (embedding-based): These retrieve chunks by comparing the semantic similarity between the query embedding and stored embeddings. In the diagram, we show an example where the user query is turned into an embedding, and the retriever searches the vector database for the most relevant chunks.
In the diagram, we illustrate how a user query is converted into an embedding, and the system searches the vector database to find the most relevant chunks.
How to Improve a RAG System
Now that you have a basic understanding of a RAG system, let's talk about areas where improvements can be made.
Rather than focusing on chunking strategies or comparing embedding models, I'll share some intuitive tips based on my experience.
1. Be selective about what you index
Imagine you have a chatbot answering customer questions. Your knowledge base might include a FAQ file with questions and answers. A common approach is to split the FAQ into question-answer pairs, create embeddings for each, and store them in a vector database.
But do you need to store embeddings for the answers too? Since users are likely to ask questions, not recite answers, it might be enough to only index the questions. This can significantly reduce storage requirements and increase retrieval speed.
2. Query classification and rewriting
Let's continue with the chatbot example. Consider these two queries:
Query 1: "What shoes do you have for women?"
Query 2: "I bought a pair of shoes last week, order number 123456. Can I return them?"
Clearly, these queries have different intents and need different types of information. The first needs product catalog data, the second needs order details and return policy info.
If you handle both queries the same way, you'll likely get poor results. Instead, classify the query's intent and create separate retrievers for each class. For order-related queries, store order info in a traditional SQL database and retrieve it with simple queries. For return policies, BM25 might be sufficient.
3. Use metadata
This naturally follows the previous point. Classifying your data and tagging it with metadata makes querying faster and more accurate. Instead of searching the entire database, you can filter by metadata first before diving deeper.
If your data includes product descriptions, customer reviews, and support articles, tag each document by type to narrow the search space efficiently.
4. Result re-ranking
Once relevant chunks are retrieved, it's important to consider their order. In an online store, you might want to re-rank products based on popularity or current customer ratings.
In cybersecurity applications, it makes sense to re-rank based on source reliability. For instance, a document from NIST should rank higher than a community post from Stack Overflow. Re-ranking helps ensure the most relevant and trustworthy content appears first.
5. Prompt placement
As LLM context windows grow, it's tempting to cram as much information as possible into the prompt. But more isn't always better. Research (like the Lost in the Middle study) shows that LLMs struggle with processing context placed in the middle of long prompts. For better results, put high-priority information at the beginning and end of the prompt instead of burying it in the middle.
6. Early and continuous evaluation
One of the most overlooked aspects of building a RAG system is evaluation. Before implementing anything, create a set of benchmark queries representing typical user interactions. Use these to test your system's performance from day one. I recently tried Langfuse and really liked it. It offers excellent observability tools that make it easy to track prompts and see how your RAG system performs over time.
7. Keep your knowledge base up to date
Lastly, a RAG system is only as good as the knowledge it retrieves. Don't forget to regularly update your knowledge base with new information and remove outdated content. Automating the update process can make it easier to keep things fresh. Set up a pipeline that automatically ingests new documents and regularly updates your databases.

Thanks for your patience in reading through some of my thoughts on this topic. Building a robust RAG system can be challenging, but with thoughtful improvements and continuous evaluation, it can become more efficient and accurate. If you're building or improving a RAG system for your LLM-based applications, feel free to reach out to discuss how I can support your project.