Bevor wir darüber sprechen, wie man ein RAG-System verbessert, sollten wir zuerst verstehen, was RAG ist und warum es wichtig ist. RAG (Retrieval-Augmented Generation) ist eine Technik, die oft verwendet wird, um die Qualität der Ausgaben von großen Sprachmodellen (LLMs) zu verbessern.
Stellen Sie sich ein LLM wie einen gut gelesenen Bibliothekar vor: Er hat eine beeindruckende Sammlung von Büchern und kann eine Vielzahl von Fragen basierend auf dem beantworten, was er gelesen hat. Aber genau wie ein Bibliothekar, der nur auf dem neuesten Stand der Bücher im Regal ist, sind LLMs auf die Daten beschränkt, mit denen sie trainiert wurden.
Eine der größten Herausforderungen bei LLMs ist, dass sie "halluzinieren" können—ähnlich wie ein Bibliothekar, der Details aus Büchern erfindet, die nicht existieren, um zu zeigen, dass er gut informiert ist. Dies passiert, weil das Modell versucht, hilfreich zu sein, aber gelegentlich Ideen erzeugt, die nicht in der Realität verankert sind.
Außerdem sind LLMs auf Daten bis zu einem bestimmten Zeitpunkt trainiert, daher wissen sie nichts über Ereignisse, die nach ihrem letzten Update stattgefunden haben. Der unten stehende Screenshot zeigt ein solches Beispiel: Als ich Deepseek nach dem aktuellen Präsidenten der Vereinigten Staaten im März 2025 fragte, erinnerte es mich daran, dass es nur Informationen bis Juli 2024 hat und sagte mir, dass Joe Biden der Präsident war.
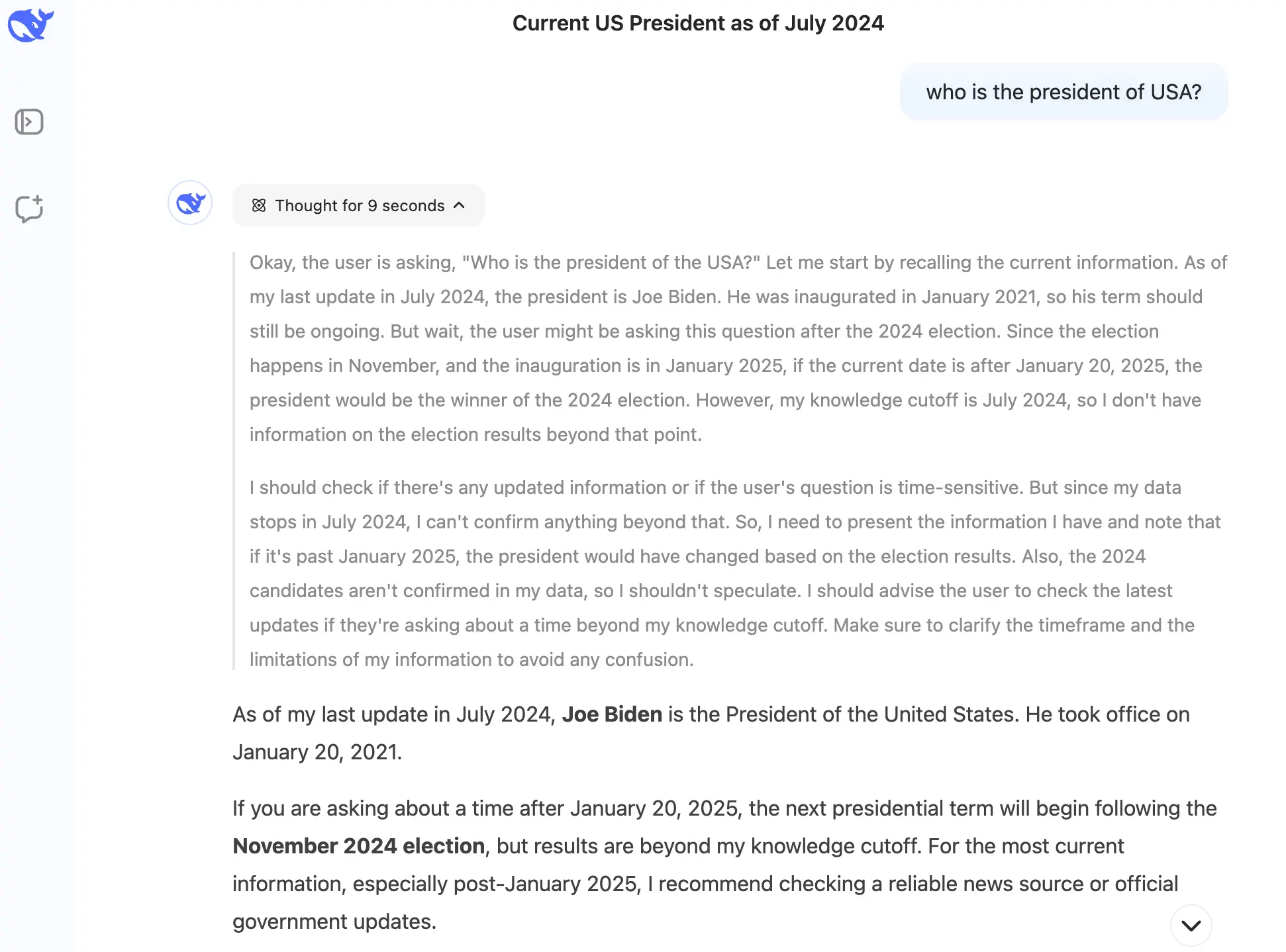
Aber es ist nicht nur veraltete Information, mit der LLMs Schwierigkeiten haben—sie können auch nicht auf vertrauliche Daten innerhalb Ihres Unternehmens zugreifen.
Hier kommt RAG ins Spiel. Durch die Bereitstellung relevanter externer Informationen für LLMs hilft RAG, die Lücken zu füllen und stellt sicher, dass der Bibliothekar (LLM) genauere und aktuellere Antworten bieten kann.
Wichtige Bausteine von RAG
Die folgende Abbildung zeigt, wie ein RAG-System aussieht. Der erste Schritt beim Aufbau eines RAG-Systems ist das Indexieren (Indexing) Ihrer Wissensbank, die Dateien, Websites, E-Mails und mehr umfassen kann. Indexing bedeutet, Ihre Daten so zu organisieren, dass sie schnell und effizient durchsucht werden können. Denken Sie an das Inhaltsverzeichnis eines Buches. Anstatt jede Seite umzublättern, können Sie direkt zu dem Abschnitt springen, den Sie benötigen.
In der Abbildung unten zeigen wir ein Beispiel für Indexing, das als vektorbasierte Indexierung bezeichnet wird. Es beginnt mit Daten aus Ihrer Wissensbank, wobei jede Datei verarbeitet und in Chunks unterteilt wird. Chunks sind kleinere Textteile, die leichter zu verwalten sind. Diese Chunks werden dann in ein Embedding-Modell eingegeben, das Embeddings erzeugt—numerische Vektoren, die den Chunk im semantischen Raum repräsentieren. Die Embeddings erfassen die semantische Bedeutung des Chunks und nicht nur die wörtliche Bedeutung.
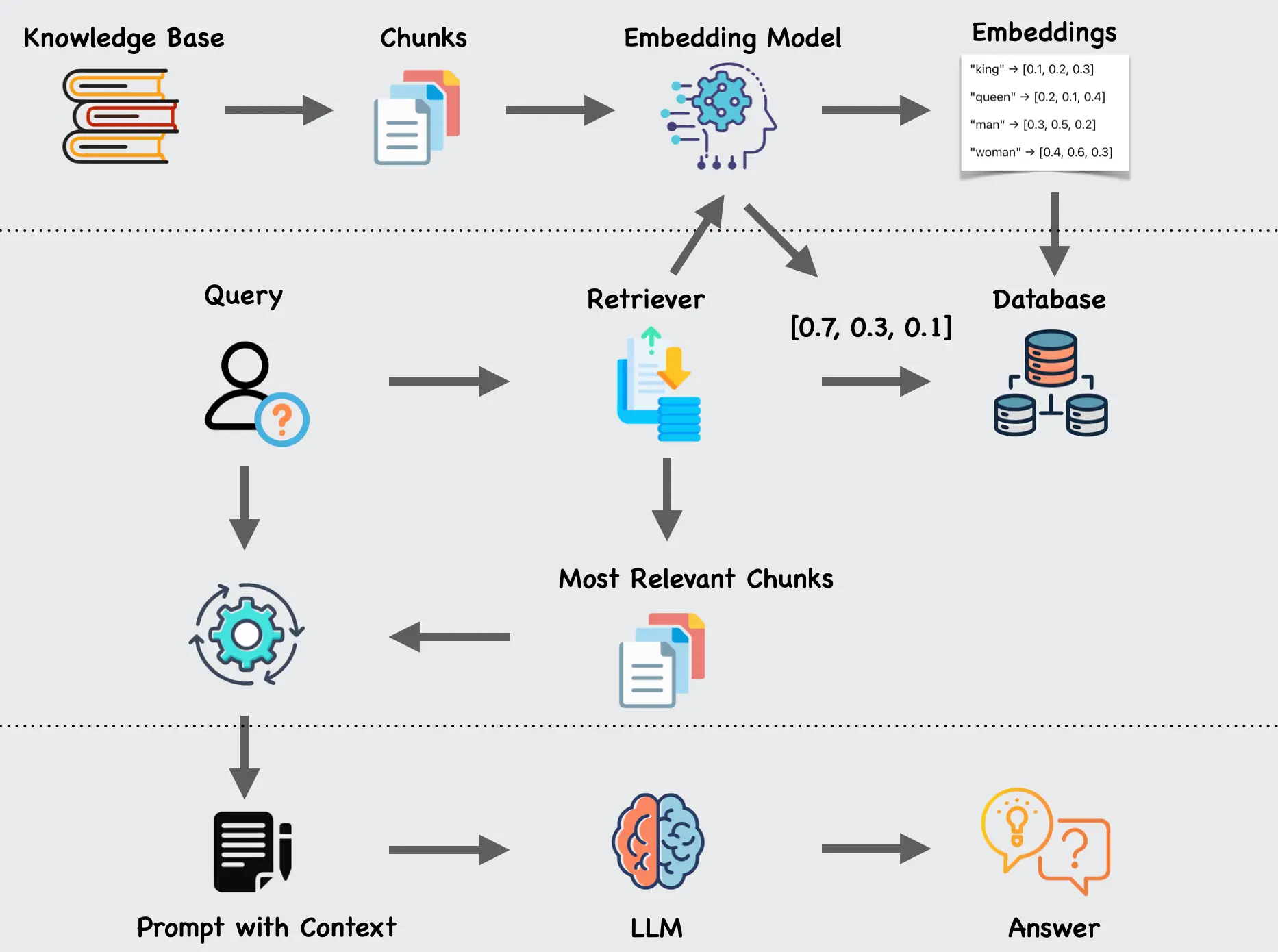
Denken Sie an Embeddings als Punkte in einem Koordinatensystem—je näher sie beieinander liegen, desto ähnlicher sind die Bedeutungen oder die Semantik der ursprünglichen Chunks.
Betrachten Sie die folgenden Chunks und deren Embeddings:
| Chunk | Embedding |
|---|---|
| Ich liebe Programmieren. | [0.1, 0.3, 0.5] |
| Ich genieße das Programmieren. | [0.2, 0.4, 0.5] |
| Python ist großartig für maschinelles Lernen. | [0.7, 0.2, 0.1] |
Da die Sätze "Ich liebe Programmieren" und "Ich genieße das Programmieren" eine ähnliche Bedeutung haben, liegen ihre Embeddings auch nahe beieinander im Koordinatensystem. Im Gegensatz dazu hat der Satz "Python ist großartig für maschinelles Lernen" eine andere Bedeutung, was zu einem weiter entfernten Embedding führt.
Sobald Sie die Embeddings haben, können Sie sie in einer Datenbank speichern, um sie später zu verwenden. Da Embeddings numerische Vektoren und keine einfachen Texte sind, wird normalerweise eine Vektordatenbank benötigt, um effizient durch sie zu suchen. Vektordatenbanken sind so konzipiert, dass sie hochdimensionale Vektoren speichern und schnelle Ähnlichkeitssuchen durchführen können.
Wenn ein Benutzer eine Anfrage an das RAG-System sendet, ist der erste Schritt, die relevanten Chunks abzurufen, die bei der Beantwortung der Anfrage helfen können. Dieser Prozess wird von einer Komponente namens "Retriever" gehandhabt, die in zwei Hauptklassen unterteilt werden kann:
-
Sparse Retrievers (Keyword-basiert): Diese finden Chunks, indem sie Schlüsselwörter aus der Anfrage mit den indexierten Daten abgleichen. Ein Beispiel ist BM25, das Dokumente basierend auf der Häufigkeit von Schlüsselwörter und der inversen Dokumenthäufigkeit rangiert. Eine Anfrage wie "beste Programmiersprache" ruft Chunks mit Schlüsselwörtern wie "beste" und "Programmiersprache"ab, die mit hoher Häufigkeit vorkommen.
-
Dense Retrievers (Embedding-basiert): Diese finden Chunks, indem sie die semantische Ähnlichkeit zwischen dem Anfrage-Embedding und den gespeicherten Embeddings vergleichen. In der Abbildung zeigen wir ein Beispiel, bei dem die Anfrage des Benutzers in ein Embedding umgewandelt wird und der Retriever in der Vektordatenbank nach den relevantesten Chunks sucht.
In der Abbildung zeigen wir ein Beispiel, bei dem die Anfrage des Benutzers in ein Embedding umgewandelt wird und das System die Vektordatenbank durchsucht, um die relevantesten Chunks zu finden.
Wie man ein RAG-System verbessern kann
Jetzt, da Sie ein grundlegendes Verständnis eines RAG-Systems haben, lassen Sie uns über Stellen sprechen, an denen Verbesserungen vorgenommen werden können.
Anstatt mich auf Chunking-Strategien oder den Vergleich von Embedding-Modellen zu konzentrieren, werde ich einige Intuitionen basierend auf meiner Erfahrung teilen.
1. Seien Sie selektiv bei dem, was Sie indexieren
Stellen Sie sich vor, Sie haben einen Chatbot, der Kundenfragen beantwortet. Ihre Wissensbank könnte eine FAQ-Datei mit Fragen und Antworten enthalten. Ein häufiger Ansatz wäre es, die FAQ in einzelne Frage-Antwort-Paare zu zerlegen, Embeddings für jedes zu erstellen und sie in einer Vektordatenbank zu speichern.
Müssen Sie jedoch auch die Embeddings für die Antworten speichern? Da Benutzer wahrscheinlich Fragen stellen, anstatt Antworten zu rezitieren, könnte es ausreichen, nur die Fragen aus Ihrer FAQ zu indexieren. Dies kann die Speicheranforderungen erheblich reduzieren und die Abrufgeschwindigkeit erhöhen.
2. Abfrageklassifizierung und Umformulierung
Lassen Sie uns mit dem Chatbot-Beispiel fortfahren. Betrachten Sie diese beiden Anfragen:
Anfrage 1: "Welche Schuhe haben Sie für Frauen?"
Anfrage 2: "Ich habe letzte Woche ein Paar Schuhe gekauft, und die Bestellnummer ist 123456. Kann ich sie zurückgeben?"
Offensichtlich haben diese Anfragen unterschiedliche Absichten und benötigen unterschiedliche Arten von Informationen. Die erste Anfrage erfordert Produktkatalogdaten, während die zweite Bestellinformationen und Rückgaberichtlinien benötigt.
Wenn Sie beide Anfragen auf dieselbe Weise behandeln, werden Sie wahrscheinlich schlechte Ergebnisse erhalten. Klassifizieren Sie stattdessen die Absicht der Anfrage und erstellen Sie separate Retriever für jede Klasse. Für Bestellabfragen speichern Sie Bestellinformationen in einer traditionellen SQL-Datenbank und rufen diese mit einfachen Abfragen ab. Für Rückgaberichtlinien reicht wahrscheinlich eine Informationsabfragetechnik wie BM25 aus.
3. Nutzen Sie Metadaten
Dieser Punkt folgt natürlich dem vorherigen. Wenn Sie Ihre Daten klassifizieren und mit Metadaten kennzeichnen, wird die Abfrage viel schneller und genauer. Statt in einer großen Datenbank zu suchen, können Sie relevante Dokumente schnell über Metadaten filtern, bevor Sie eine tiefere Suche durchführen.
Wenn Ihre Daten beispielsweise Produktbeschreibungen, Kundenbewertungen und Support-Artikel umfassen, können Sie jedes Dokument mit seinem Typ kennzeichnen, um den Suchraum effizient einzugrenzen.
4. Erneute Rangfolge der Ergebnisse
Nachdem Sie relevante Chunks abgerufen haben, ist es wichtig, über deren Reihenfolge nachzudenken. In einer Online-Shop-Anwendung möchten Sie möglicherweise Produktergebnisse basierend auf ihrer Beliebtheit oder aktuellen Kundenbewertungen neu ordnen.
Für Anwendungen in dem Bereich Cyber-Sicherheit macht es Sinn, die Rangfolge basierend auf der Zuverlässigkeit der Quelle neu zu ordnen. Ein Dokument von NIST sollte zum Beispiel höher eingestuft werden als ein Community-Beitrag von Stackoverflow. Das erneute Rangordnen hilft sicherzustellen, dass der relevanteste und zuverlässigste Inhalt zuerst erscheint.
5. Platzierung im Prompt
Wenn die Kontextfenster von großen Sprachmodellen (LLMs) größer werden, mag es verlockend erscheinen, so viele Informationen wie möglich in den Prompt zu quetschen. Aber mehr ist nicht immer besser. Forschungen (wie die Lost in the Middle-Studie) zeigen, dass LLMs Schwierigkeiten haben, den Kontext in der Mitte langer Prompts zu verarbeiten. Um bessere Ergebnisse zu erzielen, platzieren Sie hochpriorisierte Informationen am Anfang und Ende des Prompts, anstatt sie in der Mitte zu vergraben.
6. Frühzeitige und kontinuierliche Evaluierung
Einer der am meisten übersehenen Aspekte beim Aufbau eines RAG-Systems ist die Evaluierung. Bevor Sie überhaupt mit der Implementierung des Systems beginnen, erstellen Sie eine Reihe von Benchmark-Anfragen, die typische Benutzerinteraktionen darstellen. Verwenden Sie diese Anfragen, um die Leistung Ihres Systems ab dem ersten Tag zu testen. Kürzlich habe ich Langfuse ausprobiert und fand es wirklich gut. Es bietet hervorragende Observability-Tools, die es einfach machen, Ihre Prompts zu verfolgen und zu sehen, wie Ihr RAG-System im Laufe der Zeit funktioniert.
7. Aktualisieren Sie Ihre Wissensbank
Zuletzt ist ein RAG-System nur so gut wie das Wissen, das es abruft. Vergessen Sie nicht, Ihre Wissensbank regelmäßig zu aktualisieren, um neue Informationen einzubeziehen und veraltete Inhalte zu entfernen. Die Automatisierung des Update-Prozesses kann es einfacher machen, Ihre Wissensbank frisch zu halten. Richten Sie eine Pipeline ein, die automatisch neue Dokumente aufnimmt und Ihre Datenbanken regelmäßig aktualisiert.

Vielen Dank für Ihre Geduld beim Lesen einiger meiner Gedanken zu diesem Thema. Der Aufbau eines robusten RAG-Systems kann herausfordernd sein, aber mit durchdachten Verbesserungen und kontinuierlicher Evaluierung ist es möglich, es effizienter und genauer zu machen. Wenn Sie ein RAG-System für Ihre LLM-basierten Anwendungen aufbauen oder verbessern möchten, können Sie sich gerne mit mir in Verbindung setzen, um zu besprechen, wie ich Ihr Projekt unterstützen kann.